2025-01-28 14:45:17
1月28日凌晨,阿里云通義千問開源全新的視覺模型Qwen2.5-VL,推出3B、7B和72B三個尺寸版本。其中,旗艦版Qwen2.5-VL-72B在13項權威評測中奪得視覺理解冠軍。新的Qwen2.5-VL能夠更準確地解析圖像內容,突破性地支持超1小時的視頻理解,無需微調就可變身為一個能操控手機和電腦的AI視覺智能體(Visual Agents),實現給指定朋友送祝福、電腦修圖、手機訂票等多步驟復雜操作。
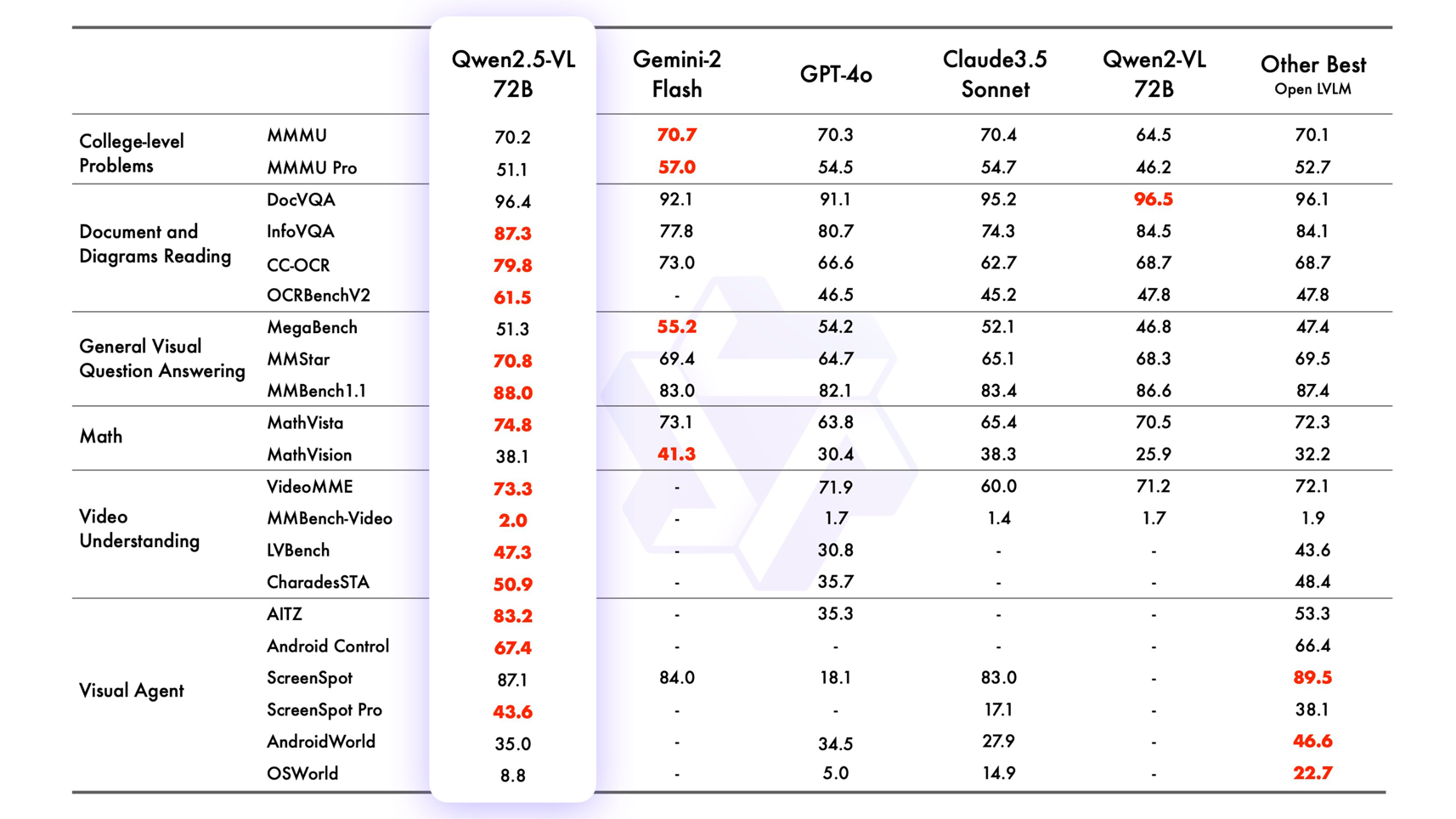
通義團隊此前曾開源Qwen-VL及Qwen2-VL兩代模型,支持開發者在手機、汽車、教育、金融、天文等不同場景進行AI探索,Qwen-VL系列模型全球總下載量超過3200萬次,是業界非常受歡迎的多模態模型。今天,Qwen-VL再度全新升級到第三代版本。根據評估,此次發布的旗艦型模型Qwen2.5-VL-72B-Instruct斬獲OCRBenchV2、MMStar、MathVista等13項評測冠軍,在包括大學水平的問答、數學、文檔理解、視覺問答、視頻理解和視覺智能體方面表現出色,全面超越GPT-4o與Claude3.5;Qwen2.5-VL-7B-Instruct 在多個任務中超越了 GPT-40-mini。
新的Qwen2.5-VL視覺知識解析能力實現了巨大飛躍:不僅能準確識別萬物,還能解析圖像的布局結構及其中的文本、圖表、圖標等復雜內容,從一張app截圖中就能分析出插圖和可點按鈕等元素;可精準定位視覺元素,擁有強大的關鍵信息抽取能力,比如準確識別和定位馬路上騎摩托車未戴頭盔的人,或是以多種格式提取發票中的核心信息并做結構化的推理輸出;OCR能力提升到全新水平,更擅長理解圖表并擁有更全面的文檔解析能力,在精準識別的內容同時還能完美還原文檔版面和格式。


圖說:Qwen2.5-VL可精準定位視覺元素,在理解圖表和文檔方面優勢顯著
Qwen2.5-VL 的視頻理解能力也大幅增強,可以更好地看清動態世界。在時間處理上,新模型引入了動態幀率(FPS)訓練和絕對時間編碼技術,使得Qwen2.5-VL不僅能夠能夠準確地理解小時級別的長視頻內容,還可以在視頻中搜索具體事件,并對視頻的不同時間段進行要點總結,從而快速、高效地幫助用戶提取視頻中蘊藏的關鍵信息。打開攝像頭,你就能與Qwen2.5-VL實時對話。
視覺感知、解析及推理能力的增強,讓大模型自動化完成任務、與真實世界進行復雜交互成為可能。Qwen2.5-VL甚至能夠直接作為視覺智能體進行操作,而無需特定任務的微調,比如讓模型直接操作電腦和手機,根據提示自動完成查詢天氣、訂機票、下載插件等多步驟復雜任務。開發者基于Qwen2.5-VL也能快速簡單開發 屬于自己的AI智能體,完成更多自動化處理和分析任務,比如自動核驗快遞單地址與照片中的門牌號是否對應,根據家庭攝像頭判斷貓咪狀況進行自動喂食,自動進行火災報警等。
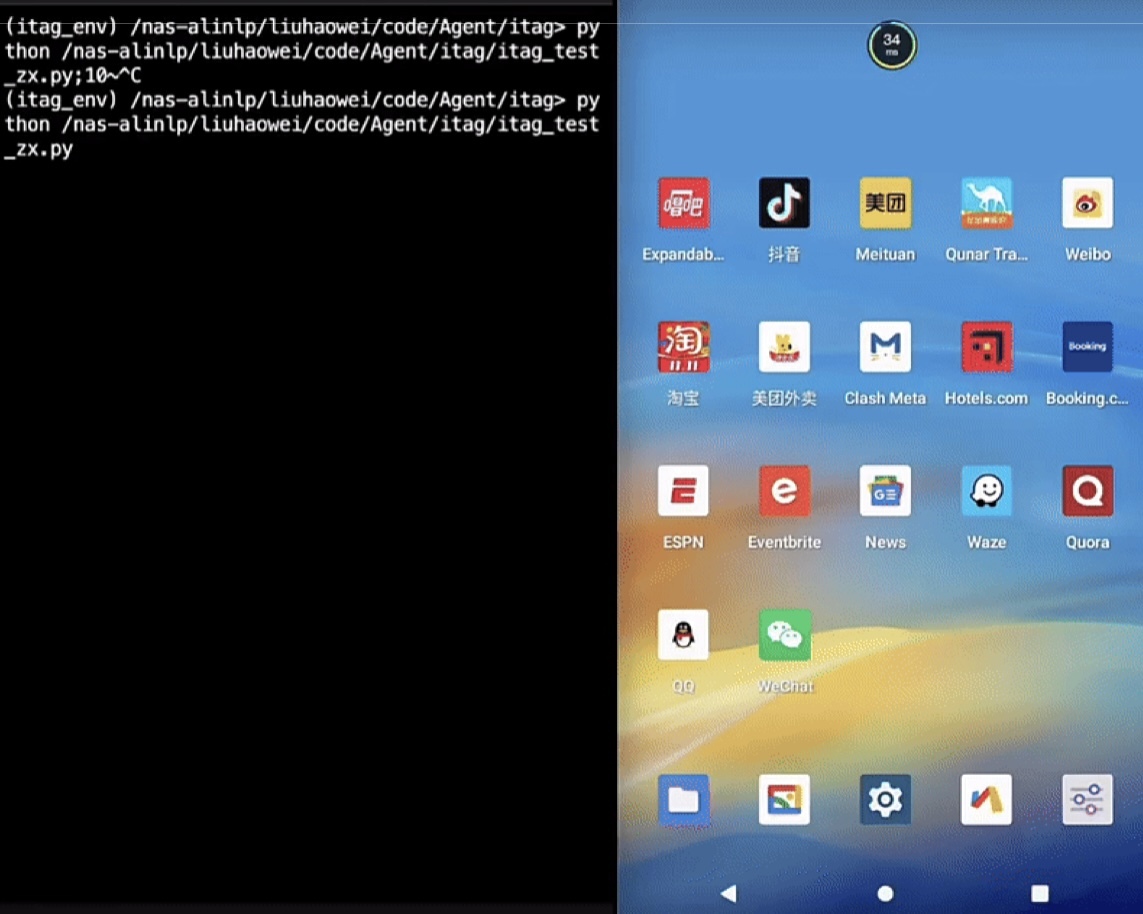
動圖:Qwen2.5-VL手機端AI Agent 演示:幫我給我的QQ好友張三,發送一條新春祝福
在模型技術方面,與Qwen2-VL相比,Qwen2.5-VL增強了模型對時間和空間尺度的感知能力,并進一步簡化了網絡結構以提高模型效率。Qwen2.5-VL創新地利用豐富的檢測框、點等坐標,讓模型直接感知和學習圖片在空間展示上的尺寸大小;同時,在時間維度也引入了動態FPS訓練和絕對時間編碼,進而擁有通過定位來捕捉事件的全新能力。而在重要的視覺編碼器設計中,通義團隊從頭開始訓練了原生動態分辨率的ViT,并采用RMSNorm和SwiGLU的結構使得ViT和LLM保持一致,讓Qwen2.5-VL擁有更簡潔高效的視覺編解碼能力。
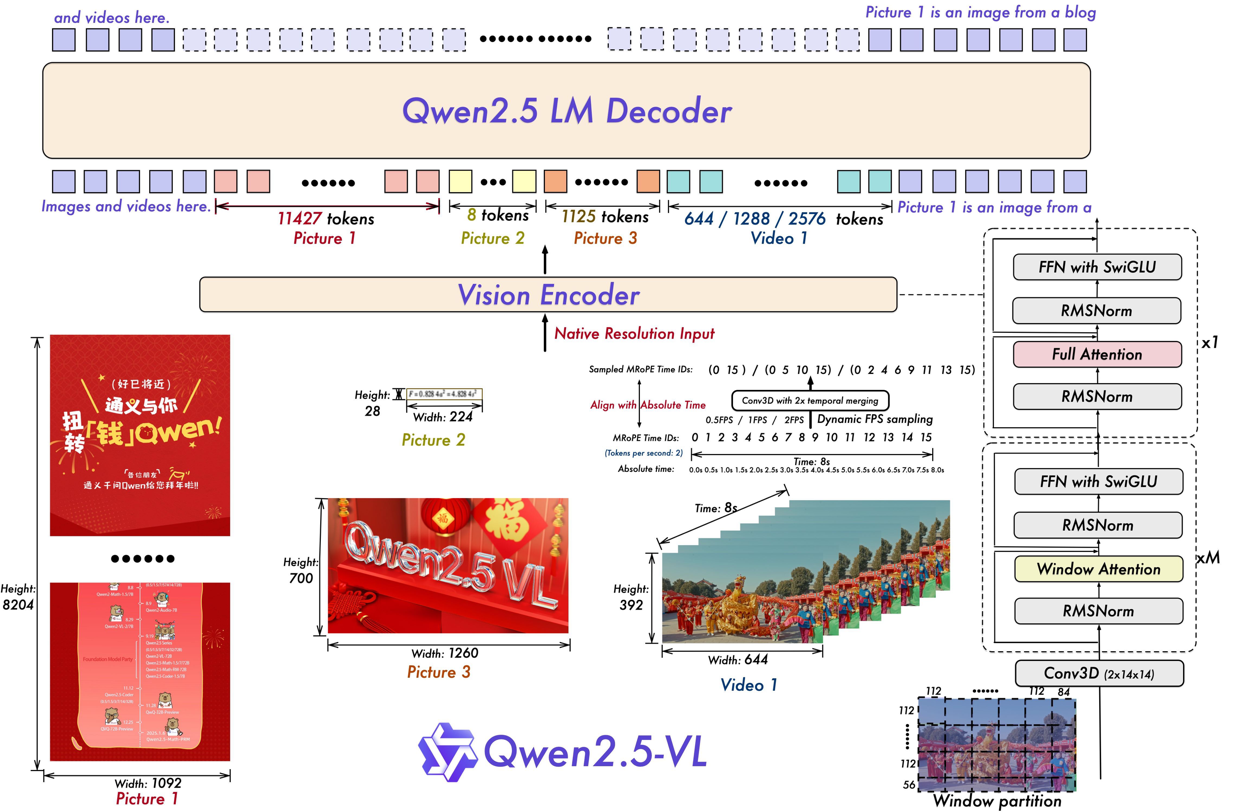
圖說:Qwen2.5-VL模型結構圖
目前,不同尺寸及量化版本的Qwen2.5-VL模型已在魔搭社區、HuggingFace等平臺開源,開發者也可以在Qwen Chat上直接體驗最新模型。
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP

Copyright ? 2025 每日經濟新聞報社版權所有,未經許可不得轉載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












