每日經濟新聞 2025-01-27 22:53:40
每經編輯|段煉
1月27日,被稱為“東方神秘力量”的DeepSeek,在資本市場掀起了滔天巨浪。
由于DeepSeek通過結構化稀疏注意力、混合專家系統、動態計算路由等技術,顯著降低了模型訓練和推理的算力消耗,由此引發了市場關于算力需求下降的擔憂。
受此影響,美股科技巨頭股價開盤集體大跌,英偉達跌超10%,市值蒸發超3500億美元(約合人民幣2.5萬億元)。臺積電跌超8%、博通跌超11%、光刻機巨頭阿斯麥(AMSL)跌超7%,微軟、甲骨文、Meta等也紛紛下跌。
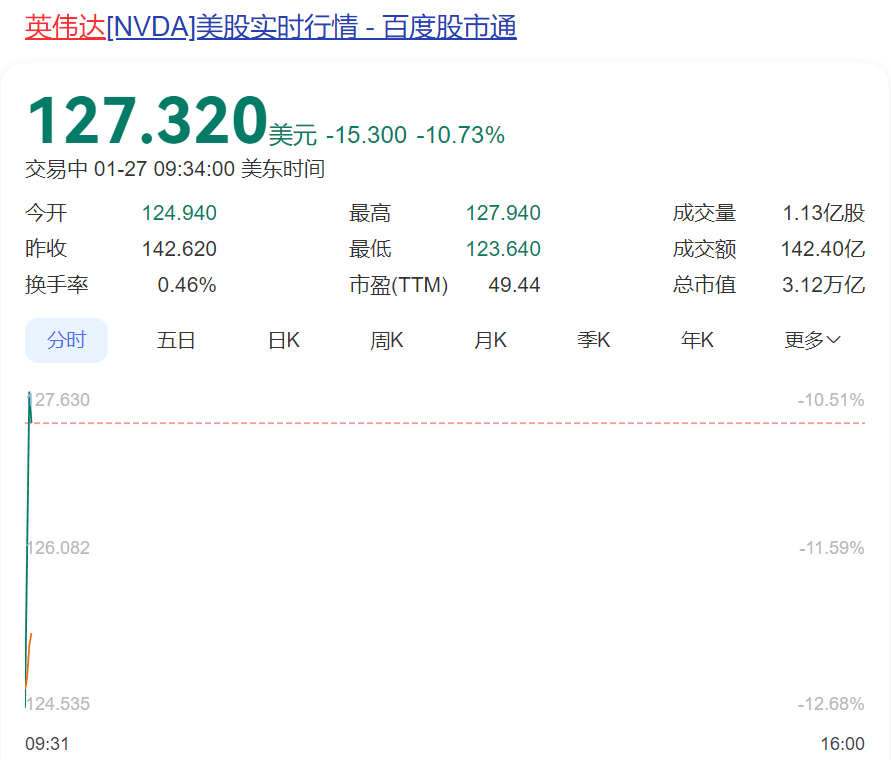
美股三大指數齊跌,納指跌超3%。

不過DeepSeek自己對此卻有不同看法,其表示英偉達股價暴跌與它無關。


AMD火速站臺
DeepSeek威脅到英偉達?
消息面上,1月27日,DeepSeek應用登頂蘋果美國地區應用商店免費APP下載排行榜,在美區下載榜上超越了ChatGPT。同日,蘋果中國區應用商店免費榜顯示,DeepSeek成為中國區第一。
此外,1月27日,據外媒報道,Meta成立了四個專門研究小組來研究量化巨頭幻方量化旗下的國產大模型DeepSeek的工作原理,并基于此來改進旗下大模型Llama。 其中兩個小組正在試圖了解幻方量化如何降低訓練和運行DeepSeek的成本;第三個研究小組則正在研究幻方量化可能使用了哪些數據來訓練其模型;第四個小組正在考慮基于DeepSeek模型屬性重構Meta模型的新技術。
據廣州日報,“DeepSeek爆火的原因主要可以歸結為兩點:性能和成本。”薩摩耶云科技集團首席經濟學家鄭磊告訴記者。DeepSeek解釋稱,R1在后訓練階段大規模使用了強化學習技術,在僅有極少標注數據的情況下,極大提升了模型推理能力。這種卓越的性能不僅吸引了科技界的廣泛關注,也讓投資界看到了其巨大的商業潛力。
最受各界關注的是,DeepSeek R1真正與眾不同之處在于它的成本——或者說成本很低。DeepSeek的R1的預訓練費用只有557.6萬美元,僅是OpenAI GPT-4o模型訓練成本的不到十分之一。同時,DeepSeek公布了API的定價,每百萬輸入tokens 1元(緩存命中)/4元(緩存未命中),每百萬輸出tokens 16元。這個收費大約是OpenAI o1運行成本的三十分之一。
OpenAI的成功來自“大力出奇跡”路線,以規模作為大模型的制勝法寶。但這也讓AI大模型的發展陷入了一個怪圈:為追求更高的性能,模型體積不斷膨脹,參數數量呈現指數級增長。這種“軍備競賽”型開發模式,帶來了驚人的能源消耗和訓練成本,難以為繼。受大模型訓練的高昂成本拖累,OpenAI在2024年的虧損額可能達到50億美元,業內專家預計到2026年其虧損將進一步攀升至140億美元。
DeepSeek的低成本意味著,大模型對算力投入的需求可能會從訓練側向推理側傾斜,即未來對推理算力的需求將成為主要驅動力。而英偉達等硬件商的傳統優勢更多集中在訓練側,這可能會對其市場地位和戰略布局產生影響。
DeepSeek-V3在僅使用2048塊H800 GPU的情況下,完成了6710億參數模型的訓練,成本僅為557.6萬美元,遠低于其他頂級模型的訓練成本(如GPT-4的10億美元)。因此,一些人認為,DeepSeek可能會顛覆英偉達在AI硬件領域的主導地位。
而就在1月25日,英偉達的“老對手”AMD還火速為DeepSeek“站臺”,宣布全新的DeepSeek-V3模型已集成至AMD InstinctGPU上。美國私人投資基金Noah's Arc Capital Management認為,DeepSeek-V3模型的突破顯著降低了AI培訓成本,使AMD GPU成為比英偉達更具有成本效益的替代品,增強了AMD的市場地位。
值得注意的是,DeepSeek創始人梁文鋒生于1985年,是浙江大學信息與通信工程專業的碩士,在他帶領下的DeepSeek對人才極其看重,不看經驗,只看能力。據多位與DeepSeek有過接觸的行業人士表述,DeepSeek的優勢之處就在于人才密度極高,且多來自于中國本土市場。DeepSeek團隊規模并不大,不到140人,工程師和研發人員幾乎都來自清北等國內頂尖高校,鮮有“海歸”,而且工作時間都不長,不少還是在讀博士。
“美國股市最大的威脅”
DeepSeek沖擊“算力競賽”?
海外媒體Vital Knowledge,德國世界報知名市場評論員Holger Zschaepitz,都不約而同地把DeepSeek稱之為“美國股市最大的威脅”。
微軟CEO納德拉近日在達沃斯一檔訪談節目中表示,中國的Deepseek發展非常迅速,在推理時間上表現出色,計算效率極高。
美股大V“THE SHORT BEAR”在社交媒體上表示,DeepSeek創造了一個AI巨頭們的痛苦時刻,而投資者必須對此敲響警鐘,“根據紅杉,美國AI公司每年必須產生約6000億美元收入來支付其AI硬件費用。但現在看來,這種冒險行為變得越來越無利可圖。”

圖片來源:X
海外知名財經博客Zerohedge1月24日撰文稱,DeepSeek的出現和其廉價的訓練成本,正在對美國此前宣布的5000億美元AI基建計劃形成巨大的打擊。
對此,1月25日,摩根大通分析師Joshua Meyers在標題為《通過DeepSeek的敘述思考——風險是真實的嗎?》的研報中寫道,雖然目前還不清楚DeepSeek在多大程度上利用了High-Flyer的約50k hopper GPU(與OpenAI據信正在訓練GPT-5的集群規模類似),但似乎很有可能的是,他們正在大幅降低成本(例如,其V2模型的推理成本據稱是GPT-4 Turbo的1/7)。DeepSeek顛覆性的主張是“更多的投資并不等于更多的創新”,這一主張開始在美國AI領域引起關注。
不過,在Joshua Meyers看來,這(DeepSeek的低成本)并不意味著(AI領域)擴張的終結,也不意味著不再需要更多的算力,更不意味著投入最多資金的一方不會獲勝(24日扎克伯格還大幅提高了Meta人工智能的資本支出)。相反,這似乎將迫使中國的競爭對手提高效率:“DeepSeek-V2能夠達到令人難以置信的訓練效率,在所需算力只有Meta的Llama 3 70B 1/5的情況下,其性能比其他開源模型更好。此外,DeepSeek-V2訓練所需的算力是GPT-4的1/20,而性能卻相差不大。”如果DeepSeek能夠降低推理成本,那么其他公司也將不得不效仿。
國外媒體也紛紛聚焦DeepSeek,并一致認為中國大模型的新進展為硅谷敲響了警鐘。1月22日,美國媒體Business Insider報道稱,DeepSeek-R1模型秉承開放精神,完全開源,為美國AI玩家帶來了麻煩。開源的先進AI可能挑戰那些試圖通過出售技術賺取巨額利潤的公司。

1月24日,美國媒體CNBC推出了長達40分鐘的節目,邀請了Perplexity CEO Aravind Srinivas來分析為何DeepSeek會引發人們對美國在AI領域的全球領先地位是否正在縮小的擔憂。
英國《金融時報》1月25日報道稱,中國小型AI初創公司DeepSeek震驚硅谷。報道聚焦資源更豐富的美國AI公司能否捍衛自己的技術優勢。

報道援引加州大學伯克利分校AI政策研究員Ritwik Gupta稱,DeepSeek最近發布的模型表明“AI能力沒有護城河”。Gupta補充說,中國的系統工程師人才庫比美國大得多,他們懂得如何充分利用計算資源來更便宜地訓練和運行模型。
對于“DeepSeek會威脅美國的AI霸權嗎?”這一問題,DeepSeek自己給出的回答是:當前AI競爭已進入"馬拉松式"的技術耐力賽。DeepSeek等中國企業的崛起,標志著全球AI發展正從單極主導轉向多極化格局。但真正改變技術權力結構,仍需在基礎理論突破、通用人工智能(AGI)等前沿領域取得實質性進展。未來5-10年,更可能形成"中美雙核,差異發展"的態勢,而非簡單的霸權更替。這場競賽的最終結果,將取決于持續創新能力的維持、產學研協同效率的提升,以及全球化協作與自主創新的動態平衡。

(聲明:文章內容和數據僅供參考,不構成投資建議。投資者據此操作,風險自擔。)
編輯|段煉 杜恒峰
校對|劉思琦
封面圖片:視覺中國(圖文無關)
每日經濟新聞綜合自證券時報、每經網、廣州日報、公開資料等
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP

Copyright ? 2025 每日經濟新聞報社版權所有,未經許可不得轉載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












