每日經濟新聞 2025-01-27 21:52:13
DeepSeek的熱度還在持續。《每日經濟新聞》記者對DeepSeek-R1與四款主流推理模型進行了對比測試,結果顯示其在基礎題上意外“翻車”,高難度問題上卻表現出色,甚至在速度上打敗了OpenAI的o1模型。DeepSeek旗下模型極低的訓練成本或許預示著AI大模型對算力投入的需求將大幅下降。AI預訓練時代或將終結。多家券商研報也指出算力需求將向推理側傾斜。
每經記者|岳楚鵬 每經編輯|蘭素英
1月20日發布的DeepSeek-R1模型讓開發公司DeepSeek在全球的熱度持續攀升。1月27日,DeepSeek接連登頂蘋果中國和美國地區應用商城的免費應用排行榜,甚至超越了大眾熟知的ChatGPT。
諸多測評結果顯示,DeepSeek旗下模型R1在多個基準測試下都能匹敵甚至超越OpenAI、谷歌和Meta的大模型,而且成本更低。在聊天機器人競技場綜合榜單上,DeepSeek-R1已經升至全類別大模型第三,其中,在風格控制類模型(StyleCtrl)分類中與頂尖推理模型OpenAI o1并列第一。其競技場得分達到1357分,略超OpenAI o1的1352分。
據外媒報道,Meta專門成立了四個專門研究小組來研究DeepSeek的工作原理,并基于此來改進旗下大模型Llama。
其中兩個小組正在試圖了解DeepSeek如何降低訓練和運行成本;第三個研究小組則在研究DeepSeek訓練模型可能用到的數據;第四個小組正在考慮基于DeepSeek模型屬性重構Meta模型。
《每日經濟新聞》記者也對炙手可熱的R1模型與四款主流推理模型——OpenAI的ChatGPT o1、谷歌的Gemini 2.0 Flash Thinking Experimental、字節跳動的豆包1.5Pro和月之暗面的Kimi 1.5——進行了對比測試。測試結果顯示,DeepSeek在難度最低的簡單邏輯推理問題上表現不佳,但在高難度問題上表現可圈可點,不僅回答正確,還在速度上擊敗了o1。
DeepSeek旗下模型極低的訓練成本或許預示著AI大模型對算力投入的需求將大幅下降。多家券商研報指出,算力需求會加速從預訓練向推理側傾斜,推理有望接力訓練,成為下一階段算力需求的主要驅動力。
《每日經濟新聞》記者對DeepSeek-R1以及市面上的幾款主流推理模型進行了對比測試,包括o1、谷歌的Gemini 2.0 Flash Thinking Experimental、字節跳動的豆包1.5Pro和月之暗面的Kimi 1.5。
記者選擇了三個問題對以上五款模型進行測試,難度依次升級(分別為一級到三級),依次評估模型的整體表現。由于DeepSeek的模型并不具備多模態功能,所以未進行多模態相關測試。
首先需要明確的是,推理模型與傳統的大語言模型在輸出方式上采用了兩種不同的模式。傳統的大語言模型對于模型的輸出采用的預測模式,即通過大規模的預訓練猜測下一個輸出應該是什么。而推理模型則具備自我事實核查能力,能夠有效避免一些常見錯誤,使之輸出邏輯更接近人類自身思考推理的過程。所以,推理模型在解決問題時通常比非推理模型需多花費幾秒到幾分鐘,在物理、科學和數學等領域,其可靠性更高,但在常識領域可能有著效率不高的問題。
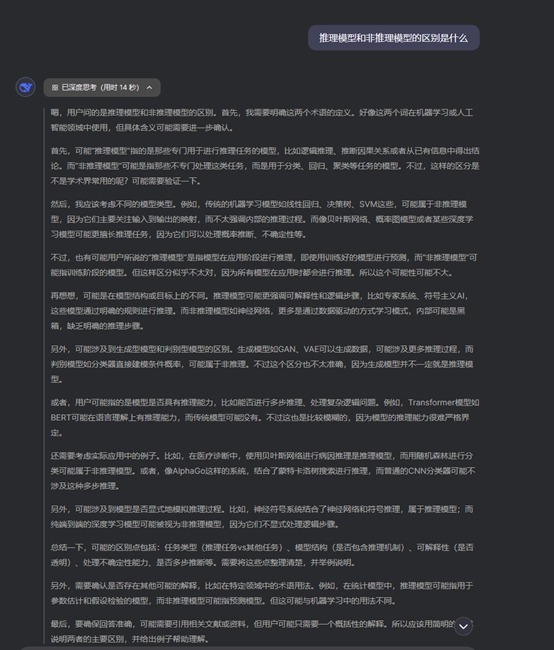
DeepSeek推理過程示意圖
難度I|三個燈泡問題:五大模型全部通關
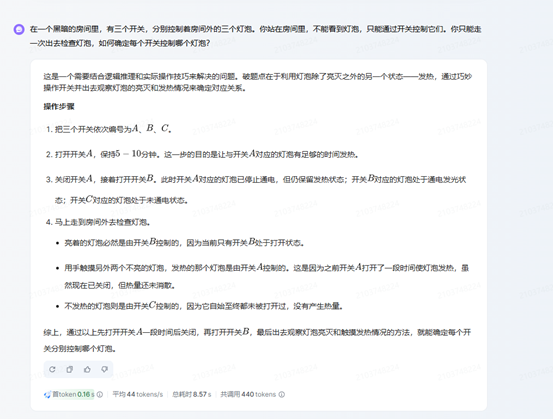
首先,記者選擇了一道簡單的思維問題:在一個黑暗的房間里,有三個開關,分別控制著房間外的三個燈泡。你站在房間里,不能看到燈泡,只能通過開關控制它們。你只能走一次出去檢查燈泡,如何確定每個開關控制哪個燈泡?
五個模型都很快得出了正確答案,在這個簡單的問題上沒有分出區別。
豆包
DeepSeek
Kimi

Gemini

o1
難度II|囚犯帽子顏色推理:DeepSeek、Kimi犯錯,Gemini耗時最短且完全正確
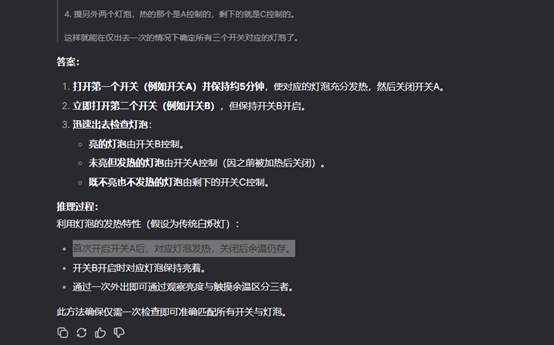
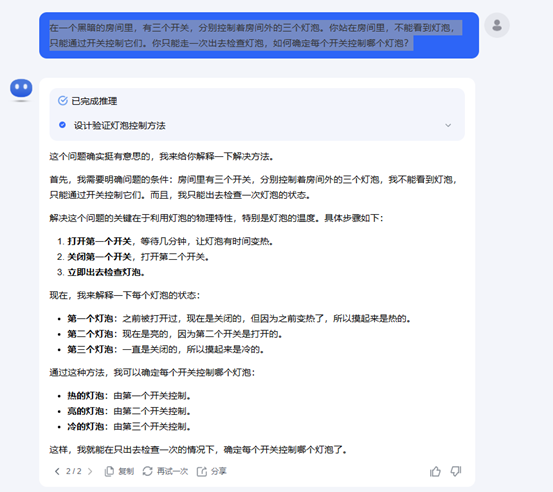
接下來問題升級:有四位囚犯排隊站好,囚犯1號能看見囚犯2號和囚犯3號;囚犯2號可以看見囚犯3號;囚犯3號看不見任何人;囚犯4號也看不見任何人。他們知道一共有4頂帽子,2黑2白,但并不知道自己頭頂的帽子是什么顏色。請問誰會是第一個知道自己頭頂的帽子是什么顏色并且迅速喊出來的人?
在這個問題上,DeepSeek和Kimi都犯錯了,兩者在推理過程中推導出了一種情況,但正確選項應該是兩種。
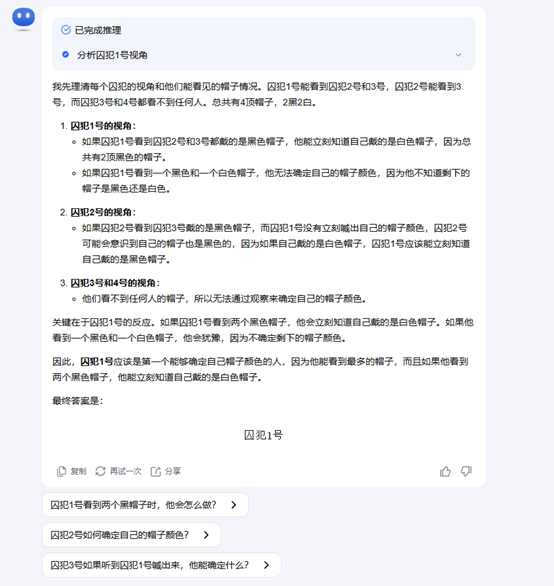
Kimi

DeepSeek
而Gemini、豆包和o1都回答正確。其中,Gemini推理速度最快,僅用了6.8秒就得出了結果,最慢的是o1,耗時1分02秒。
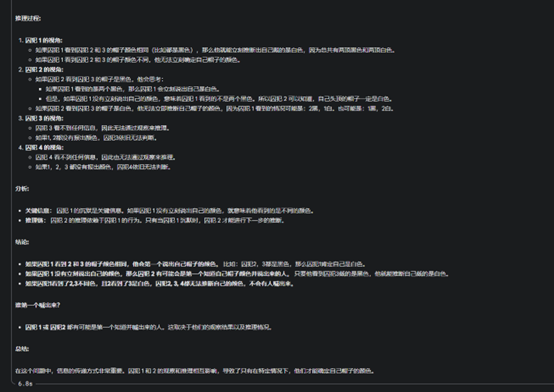
Gemini

o1
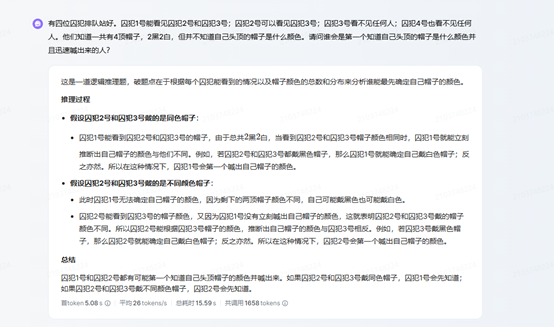
豆包
難度III|研究生級別數學題:DeepSeek-R1完勝,且用時最短
評測結果顯示,DeepSeek在科學領域如數學能力上排名第一。于是,記者找來了一道研究生級別的數學題進行測試:找出所有階為147且不包含階為49的元素的兩兩不同同構群(出自美國南加州大學博士資格考試)。
在這一問題上,DeepSeek-R1沒有“辜負”評測,表現最好,找出了三個解。除o1外的其他模型只找出了兩個解,而且,Kimi在推理過程中還開啟了聯網查詢功能進行輔助推理,但仍然少了一個解。
雖然o1也找出了三個解,但耗時更長,用了4分17秒得出答案,而DeepSeek-R1只花費了2分18秒。

DeepSeek

o1

豆包
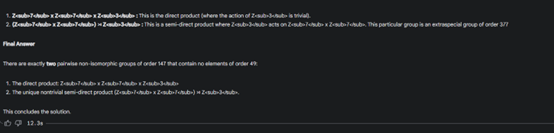
Gemini

Kimi
綜合各項測試來看,DeepSeek存在一個反常識的問題,即在難度不高的問題上表現不如其他模型好,甚至可能會出現其他模型不會出現的錯誤。但是當難度提升到專家級別的程度上時,DeepSeek的表現反而變成了最好的模型。
這就是說,對于需要專業知識輔導的從業人員或研究人員來說,DeepSeek是一個好的選擇。
1月27日,蘋果App Store中國區免費榜顯示,近一周全球刷屏的DeepSeek一舉登上首位。同時,DeepSeek在美國區蘋果App Store免費榜從前一日的第六位飆升至第一位,超越ChatGPT、Meta旗下的社交媒體平臺Threads、Google Gemini,以及Microsoft Copilot等AI產品。

許多科技界人士都在大肆宣揚該公司所取得的成就及其對AI領域的意義。
例如,著名投資公司A16z創始人馬克安德森27日表示,DeepSeek-R1是AI的斯普特尼克時刻(注:這是指1957年10月4日蘇聯搶先美國成功發射斯普特尼克1號人造衛星,令西方世界陷入一段恐懼和焦慮的時期)。
DeepSeek-R1在一些AI基準測試上匹敵甚至超越了OpenAI的o1模型。DeepSeek-R1在聊天機器人競技場綜合榜單上排名第三,與頂尖推理模型o1并列。
在高難度提示詞、代碼和數學等技術性極強的領域,DeepSeek-R1拔得頭籌,位列第一。
在風格控制方面,DeepSeek-R1與o1并列第一,意味著模型在理解和遵循用戶指令,并按照特定風格生成內容方面表現出色。
在高難度提示詞與風格控制結合的測試中,DeepSeek-R1與o1也并列第一,進一步證明了其在復雜任務和精細化控制方面的強大能力。
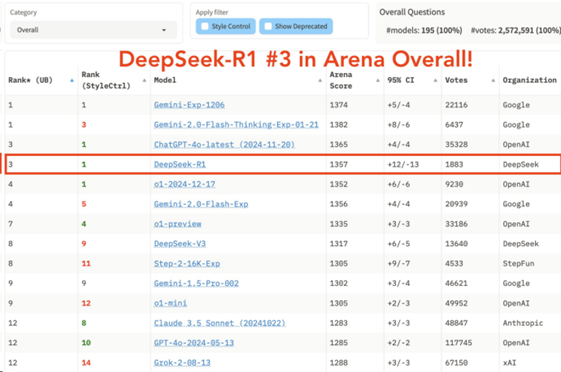
圖片來源:聊天機器人競技場
Artificial-Analysis對DeepSeek-R1的初始基準測試結果也顯示,DeepSeek-R1在AI分析質量指數中取得第二高分,價格是o1的約三十分之一。
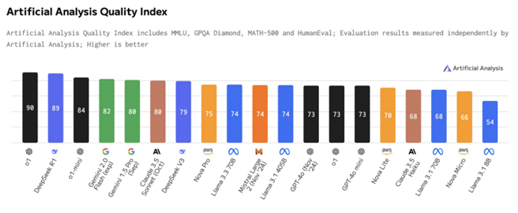
圖片來源:Artificial-Analysis
DeepSeek旗下模型極低的訓練成本或許預示著AI大模型對算力投入的需求將大幅下降。
“AI預訓練時代無疑將終結。”2024年12月13日,在溫哥華NeurIPS大會上,OpenAI聯合創始人兼前首席科學家伊利亞•蘇茨克維爾(Ilya Sutskever)直言。
在這場演講中,Ilya Sutskever將數據比作化石燃料,而燃料終將耗盡。“算力在增長,但數據卻沒有增長,因為我們只有一個互聯網……我們已經達到了數據峰值,不會再有更多數據了,我們必須處理好現有的數據。”現有數據仍可推動AI進一步發展,業內也正在竭力挖掘新數據進行訓練,這種情況最終將迫使行業改變目前的AI模型訓練方式。他預計,下一代AI模型將是真正的AI Agent,且具備推理能力。
預訓練是指使用大量數據訓練AI模型的過程,通常需要極高的計算能力和存儲資源。訓練過程通常在數據中心完成,耗時較長,成本高昂。推理是指將訓練好的模型應用于實際任務(如生成文本、識別圖像、推薦商品等),通常需要低延遲和高吞吐量。推理過程可以在云端或邊緣設備(如手機、自動駕駛汽車)上進行。
推理模型其最突出的地方在于,在給出回答之前,模型會思考,通過產生一個很長的內部思維鏈(CoT),逐步推理,模仿人類思考復雜問題的過程。
隨著各類大模型的成熟,許多企業和開發者可以直接使用預訓練模型,而不需要從頭訓練。對于特定任務,企業通常只需對預訓練模型進行微調,而不需要大規模訓練,這減少了對訓練算力的需求。預訓練時代或許行將落幕,推理正在崛起。
近幾日,多家券商研報都指出,算力需求會加速從預訓練向推理側傾斜,推理有望接力訓練,成為下一階段算力需求的主要驅動力。
巴克萊12月的報告預計,AI推理計算需求將快速提升,預計其將占通用人工智能總計算需求的70%以上,推理計算的需求甚至可以超過訓練計算需求,達到后者的4.5倍。英偉達GPU目前在推理市場中市占率約80%,但隨著大型科技公司定制化ASIC芯片不斷涌現,這一比例有望在2028年下降至50%左右。
免責聲明:本文內容與數據僅供參考,不構成投資建議,使用前請核實。據此操作,風險自擔。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP

Copyright ? 2025 每日經濟新聞報社版權所有,未經許可不得轉載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112













